Ph.D. Candidate in Computer Science | Purdue University Advisor: Prof. Ninghui Li Focus: Privacy and Security for Large Language Models
Research
I design and evaluate membership inference attacks to quantify privacy leakage in generative AI systems. My work measures how much training data modern LLMs expose and develops mitigation strategies that balance model utility with data confidentiality—addressing a fundamental challenge for safe AI deployment.
Beyond privacy quantification, my research encompasses computational creativity (controllable generation and multi-modal human-robot interaction) and adversarial defenses against prompt-level jailbreaks and data poisoning. These efforts contribute to making AI systems both more empowered and more trustworthy.
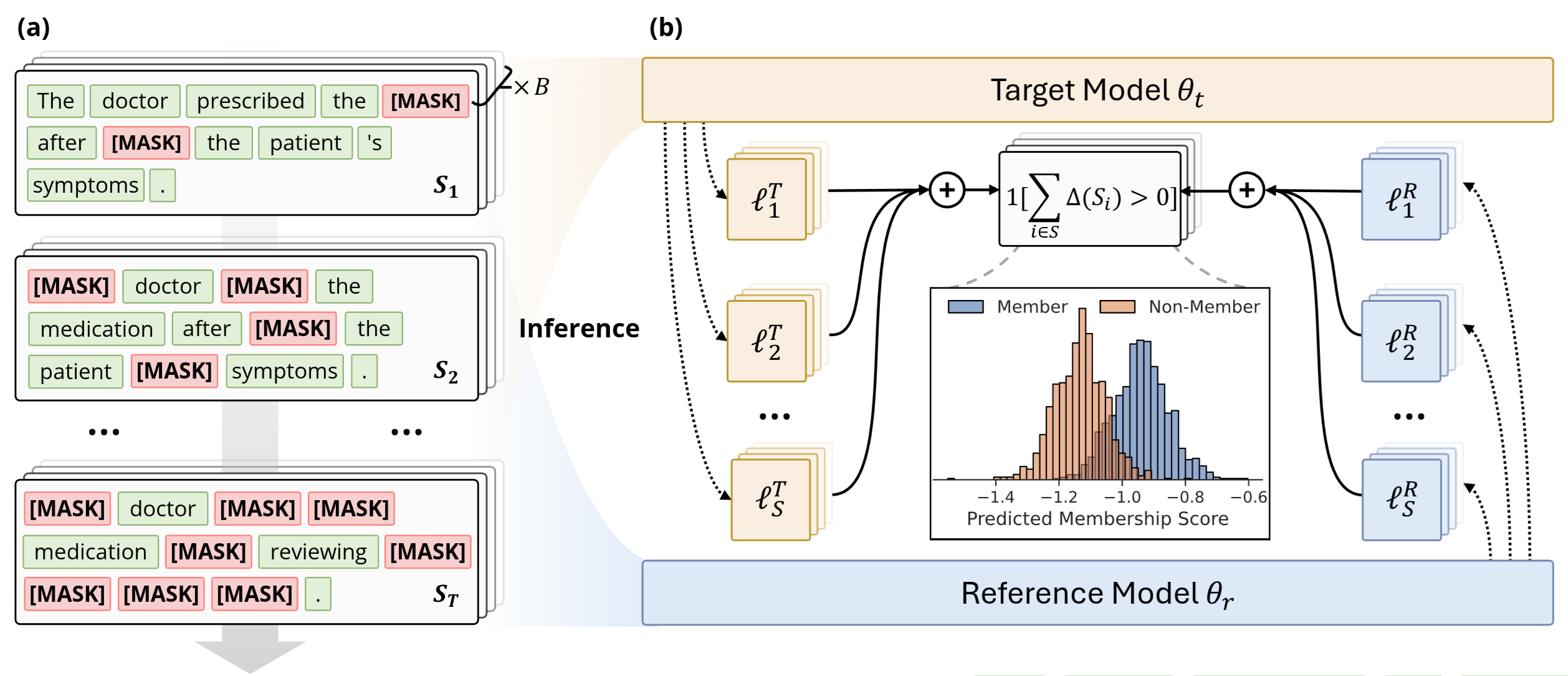
Diffusion Language Models (DLMs) represent a promising alternative to autoregressive language models, using bidirectional masked token prediction. Yet their susceptibility to privacy leakage via Membership Inference Attacks (MIA) remains critically underexplored. This paper presents the first systematic investigation of MIA vulnerabilities in DLMs. Unlike the autoregressive models’ single fixed prediction pattern, DLMs’ multiple maskable configurations exponentially increase attack opportunities. This ability to probe many independent masks dramatically improves detection chances. To exploit this, we introduce SAMA (Subset-Aggregated Membership Attack), which addresses the sparse signal challenge through robust aggregation. SAMA samples masked subsets across progressive densities and applies sign-based statistics that remain effective despite heavy-tailed noise. Through inverse-weighted aggregation prioritizing sparse masks’ cleaner signals, SAMA transforms sparse memorization detection into a robust voting mechanism. Experiments on nine datasets show SAMA achieves 30% relative AUC improvement over the best baseline, with up to 8x improvement at low false positive rates. These findings reveal significant, previously unknown vulnerabilities in DLMs, necessitating the development of tailored privacy defenses.
@article{chen2025membership,title={Membership Inference Attacks on Finetuned Diffusion Language Models},author={Chen, Yuetian and Zhang, Kaiyuan and Du, Yuntao and Stoppa, Edoardo and Fleming, Charles and Kundu, Ashish and Ribeiro, Bruno and Li, Ninghui},journal={The Fourteenth International Conference on Learning Representations},year={2026},}
USENIX’26
Window-based Membership Inference Attacks Against Fine-tuned Large Language Models
Yuetian Chen, Yuntao Du, Kaiyuan Zhang, and 4 more authors
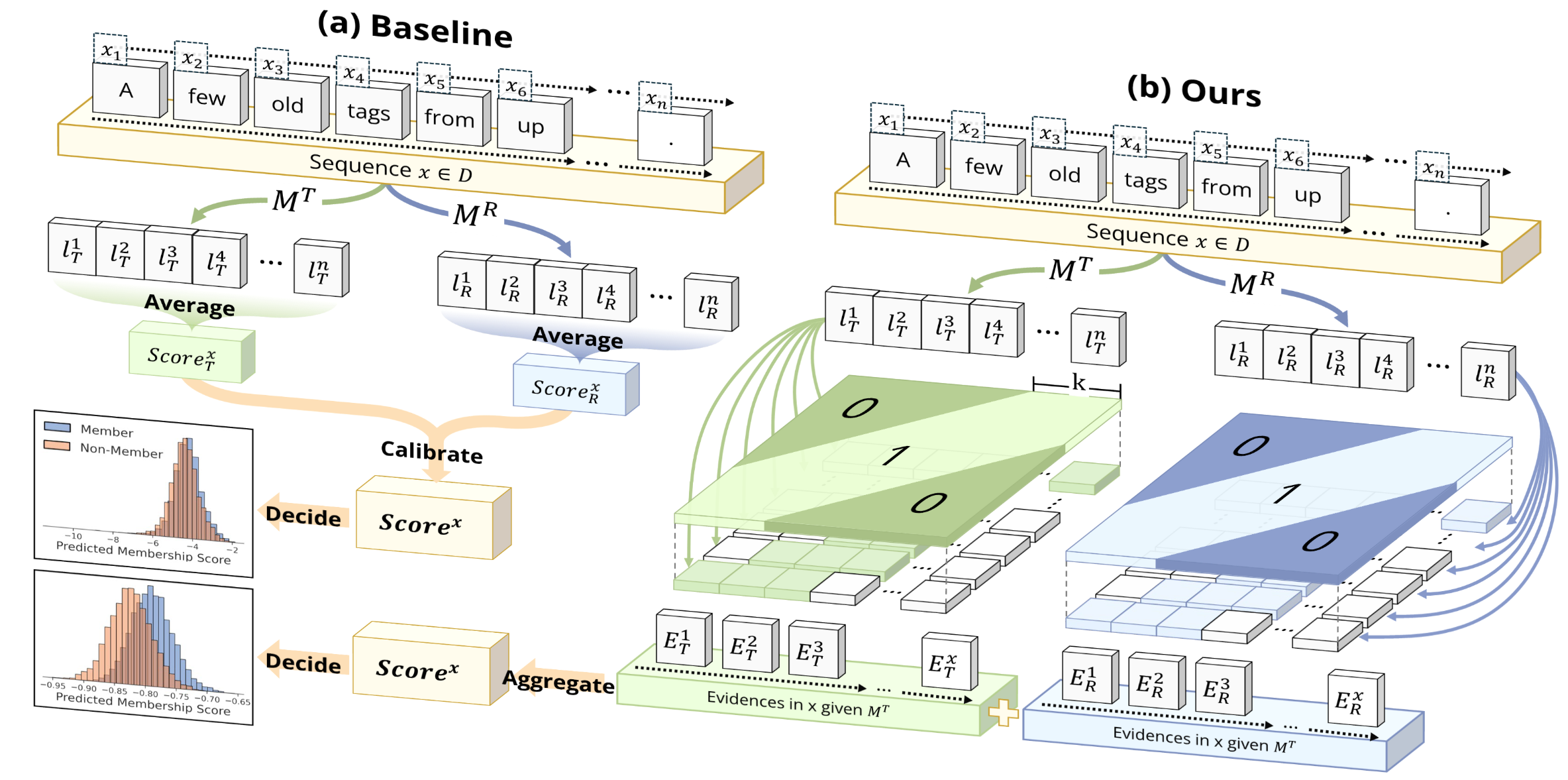
Most membership inference attacks (MIAs) against Large Language Models (LLMs) rely on global signals, like average loss, to identify training data. This approach, however, dilutes the subtle, localized signals of memorization, reducing attack effectiveness. We challenge this global-averaging paradigm, positing that membership signals are more pronounced within localized contexts. We introduce WBC (Window-Based Comparison), which exploits this insight through a sliding window approach with sign-based aggregation. Our method slides windows of varying sizes across text sequences, with each window casting a binary vote on membership based on loss comparisons between target and reference models. By ensembling votes across geometrically spaced window sizes, we capture memorization patterns from token-level artifacts to phrase-level structures. Extensive experiments across eleven datasets demonstrate that WBC substantially outperforms established baselines, achieving higher AUC scores and 2-3 times improvements in detection rates at low false positive thresholds. Our findings reveal that aggregating localized evidence is fundamentally more effective than global averaging, exposing critical privacy vulnerabilities in fine-tuned LLMs.
@article{chen2025window,title={Window-based Membership Inference Attacks Against Fine-tuned Large Language Models},author={Chen, Yuetian and Du, Yuntao and Zhang, Kaiyuan and Fleming, Charles and Kundu, Ashish and Ribeiro, Bruno and Li, Ninghui},journal={35th USENIX Security Symposium},year={2026},}
USENIX’26
Imitative Membership Inference Attack
Yuntao Du, Yuetian Chen, Hanshen Xiao, and 2 more authors
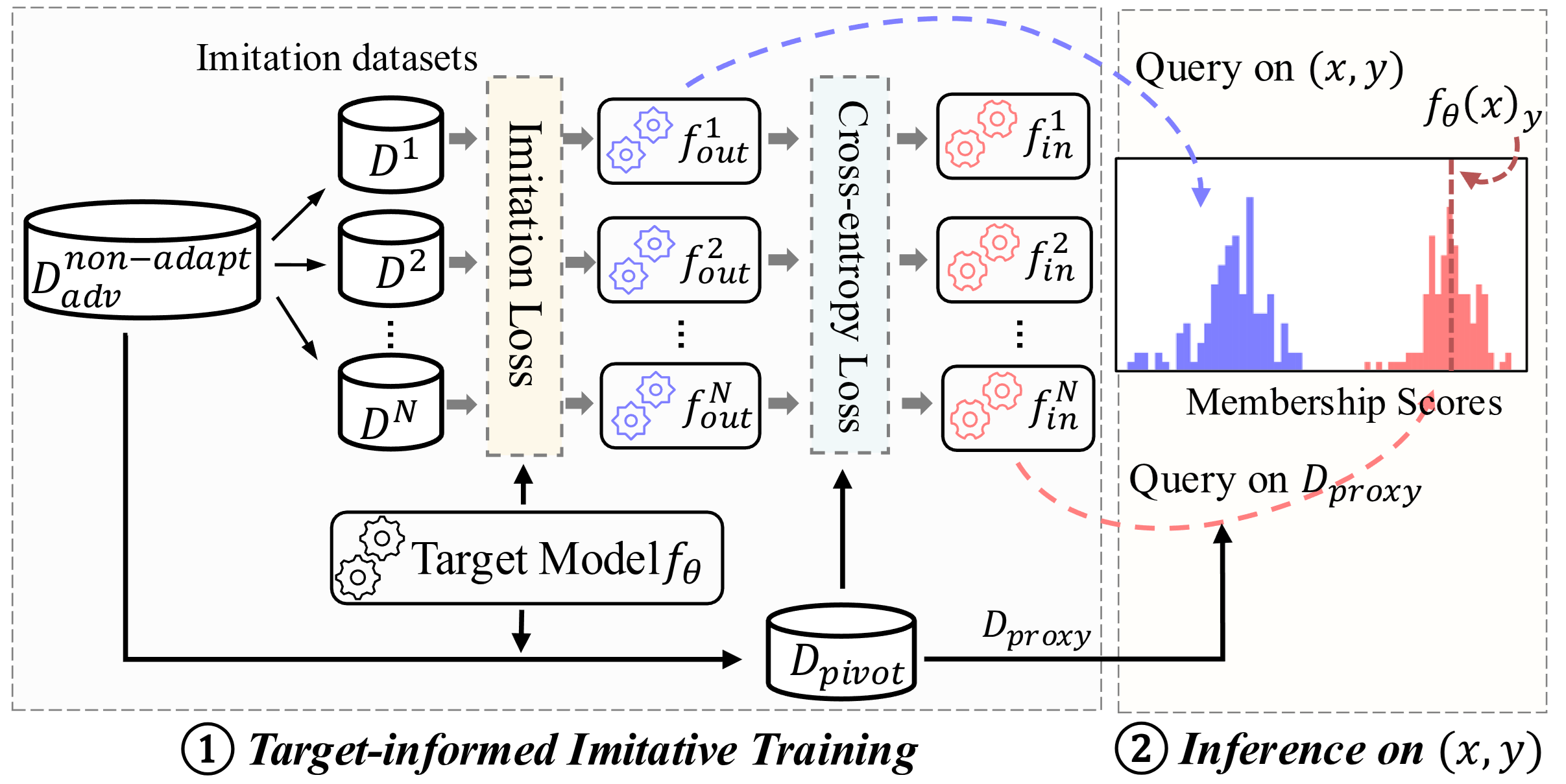
A Membership Inference Attack (MIA) assesses how much a target machine learning model reveals about its training data by determining whether specific query instances were part of the training set. State-of-the-art MIAs rely on training hundreds of shadow models that are independent of the target model, leading to significant computational overhead. In this paper, we introduce Imitative Membership Inference Attack (IMIA), which employs a novel imitative training technique to strategically construct a small number of target-informed imitative models that closely replicate the target model’s behavior for inference. Extensive experimental results demonstrate that IMIA substantially outperforms existing MIAs in various attack settings while only requiring less than 5% of the computational cost of state-of-the-art approaches.
@article{du2025imitative,title={Imitative Membership Inference Attack},author={Du, Yuntao and Chen, Yuetian and Xiao, Hanshen and Ribeiro, Bruno and Li, Ninghui},journal={35th USENIX Security Symposium},year={2026},}
NDSS’26
Cascading and Proxy Membership Inference Attack
Yuntao Du, Jiacheng Li, Yuetian Chen, and 5 more authors
In Network and Distributed System Security Symposium, 2026
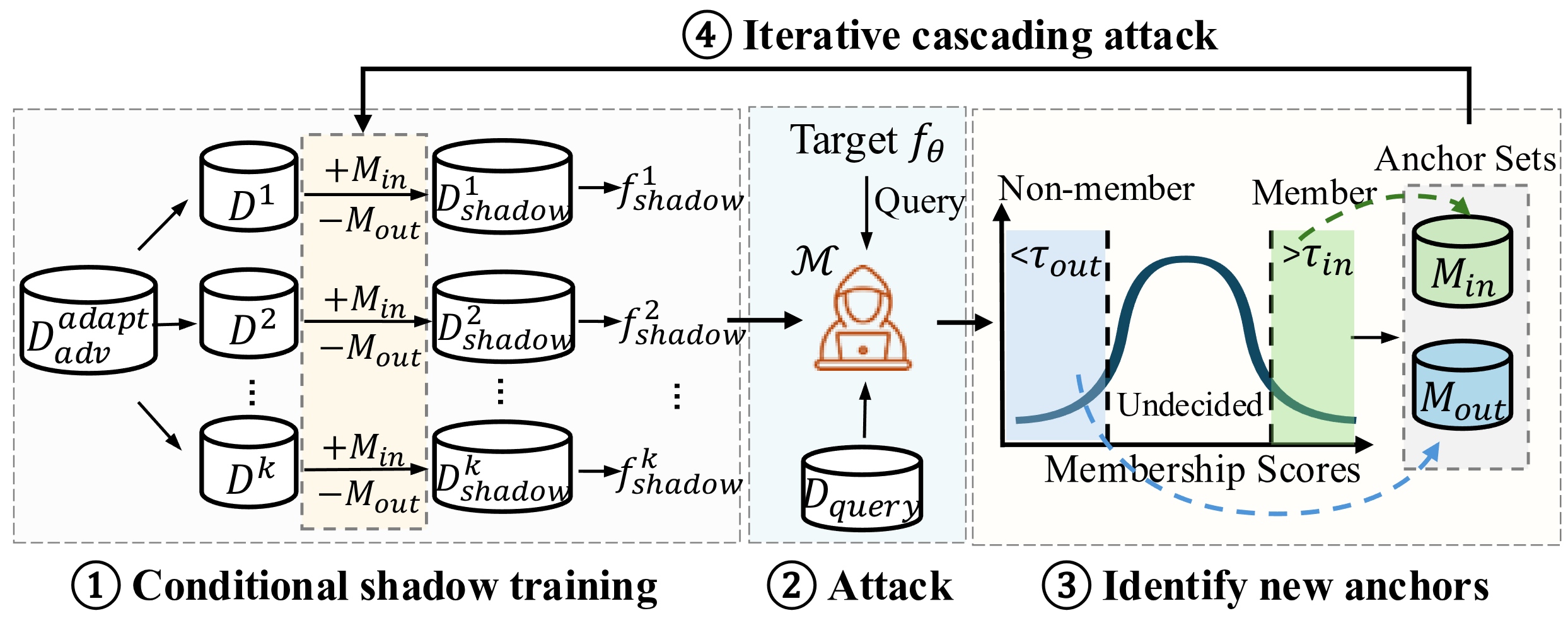
A Membership Inference Attack (MIA) assesses how much a trained machine learning model reveals about its training data by determining whether specific query instances were included in the dataset. We classify existing MIAs into adaptive or non-adaptive, depending on whether the adversary is allowed to train shadow models on membership queries. In the adaptive setting, where the adversary can train shadow models after accessing query instances, we highlight the importance of exploiting membership dependencies between instances and propose an attack-agnostic framework called Cascading Membership Inference Attack (CMIA), which incorporates membership dependencies via conditional shadow training to boost membership inference performance. In the non-adaptive setting, where the adversary is restricted to training shadow models before obtaining membership queries, we introduce Proxy Membership Inference Attack (PMIA). PMIA employs a proxy selection strategy that identifies samples with similar behaviors to the query instance and uses their behaviors in shadow models to perform a membership posterior odds test for membership inference. We provide theoretical analyses for both attacks, and extensive experimental results demonstrate that CMIA and PMIA substantially outperform existing MIAs in both settings, particularly in the low false-positive regime, which is crucial for evaluating privacy risks.
@inproceedings{du2026cascading,title={Cascading and Proxy Membership Inference Attack},author={Du, Yuntao and Li, Jiacheng and Chen, Yuetian and Zhang, Kaiyuan and Yuan, Zhizhen and Xiao, Hanshen and Ribeiro, Bruno and Li, Ninghui},booktitle={Network and Distributed System Security Symposium},year={2026},}
USENIX’25
SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference Attacks
Kaiyuan Zhang, Siyuan Cheng, Hanxi Guo, and 8 more authors
Large language models (LLMs) have achieved remarkable success and are widely adopted for diverse applications. However, fine-tuning these models often involves private or sensitive information, raising critical privacy concerns. In this work, we conduct the first comprehensive study evaluating the vulnerability of fine-tuned LLMs to membership inference attacks (MIAs). Our empirical analysis demonstrates that MIAs exploit the loss reduction during fine-tuning, making them highly effective in revealing membership information. These findings motivate the development of our defense. We propose SOFT (\textbfSelective data \textbfObfuscation in LLM \textbfFine-\textbfTuning), a novel defense technique that mitigates privacy leakage by leveraging influential data selection with an adjustable parameter to balance utility preservation and privacy protection. Our extensive experiments span six diverse domains and multiple LLM architectures and scales. Results show that SOFT effectively reduces privacy risks while maintaining competitive model performance, offering a practical and scalable solution to safeguard sensitive information in fine-tuned LLMs.
@article{zhang2025soft,title={SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference Attacks},author={Zhang, Kaiyuan and Cheng, Siyuan and Guo, Hanxi and Chen, Yuetian and Su, Zian and An, Shengwei and Du, Yuntao and Fleming, Charles and Kundu, Ashish and Zhang, Xiangyu and Li, Ninghui},journal={34th USENIX Security Symposium},year={2025},}
LREC-COLING’24
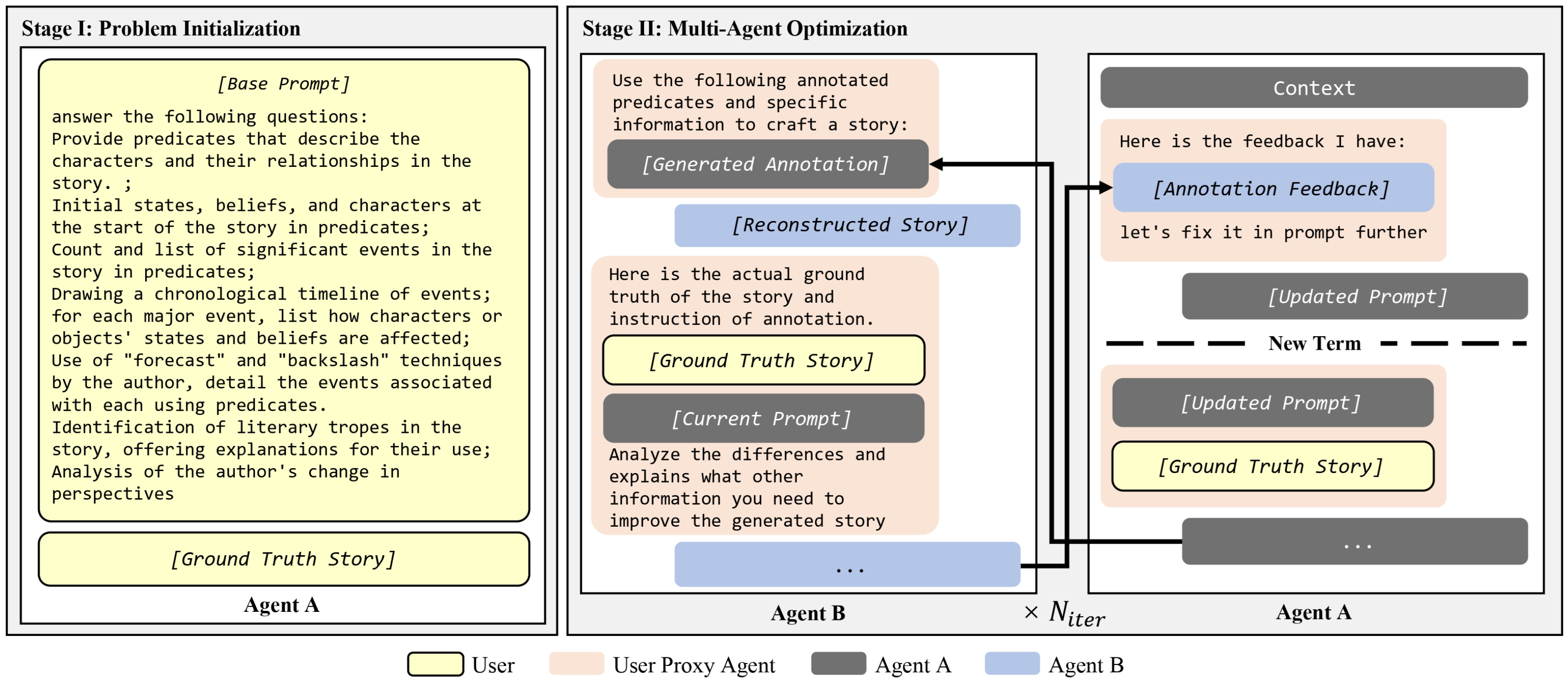
Reflections & Resonance: Two-Agent Partnership for Advancing LLM-based Story Annotation
Yuetian Chen and Mei Si
In Joint International Conference on Computational Linguistics, Language Resources and Evaluation, 2024
We introduce a novel multi-agent system for automating story annotation through the generation of tailored prompts for a large language model (LLM). This system utilizes two agents: Agent A is responsible for generating prompts that identify the key information necessary for reconstructing the story, while Agent B reconstructs the story from these annotations and provides feedback to refine the initial prompts. Human evaluations and perplexity scores revealed that optimized prompts significantly enhance the model’s narrative reconstruction accuracy and confidence, demonstrating that dynamic interaction between agents substantially boosts the annotation process’s precision and efficiency. Utilizing this innovative approach, we created the “StorySense” corpus, containing 615 stories, meticulously annotated to facilitate comprehensive story analysis. The paper also demonstrates the practical application of our annotated dataset by drawing the story arcs of two distinct stories, showcasing the utility of the annotated information in story structure analysis and understanding.
@inproceedings{chen-si-2024-reflections,title={Reflections {\&} Resonance: Two-Agent Partnership for Advancing {LLM}-based Story Annotation},author={Chen, Yuetian and Si, Mei},editor={Calzolari, Nicoletta and Kan, Min-Yen and Hoste, Veronique and Lenci, Alessandro and Sakti, Sakriani and Xue, Nianwen},booktitle={Joint International Conference on Computational Linguistics, Language Resources and Evaluation},year={2024},address={Torino, Italia},publisher={ELRA and ICCL},url={https://aclanthology.org/2024.lrec-main.1206},pages={13813--13818},}